
FOSDEM 2021, Monitoring & Observability room

Protože první den na FOSDEM 2021 v Golang room se mi líbil, podíval jsem se, co ještě zajímavého dávají druhý den. Jednotlivých roomů bylo hodně, ale nic moc mě nezaujalo (že by se v open source nic zajímavého nedělo? 🤔). Nicméně protože jsem se nedáno hodně zabýval Fluentd a před dvěma lety zase Prometheem, vybral jsem si nakonec Monitoring and Observability room. A nebylo to špatný.
Observability for beginners
Atibhi Agrawal byla na stáži v Grafana Labs, kde — logicky — přičuchla k distribuovanému monitoringu. Její přednáška byla krátká 10minutovka, velmi, velmi lehký úvod do observability a jak se to liší/doplňuje s monitoringem.
Observability zahrnuje: logging, metrics a tracing, které spolu dohromady vytvářejí kontext, co se v systému děje. Letmo zmínila pár nástrojů, které jsou de facto standard pro monitorování v cloudu: Prometheus, Fluentd, Jaeger a (samozřejmě) Grafana.
Dobrá rada (pro začátečníky) byla udělat si side-projekt a nastavit pro něj metriky, logování a traceování.
A Google Monitoring System, Monarch… in Open Source?
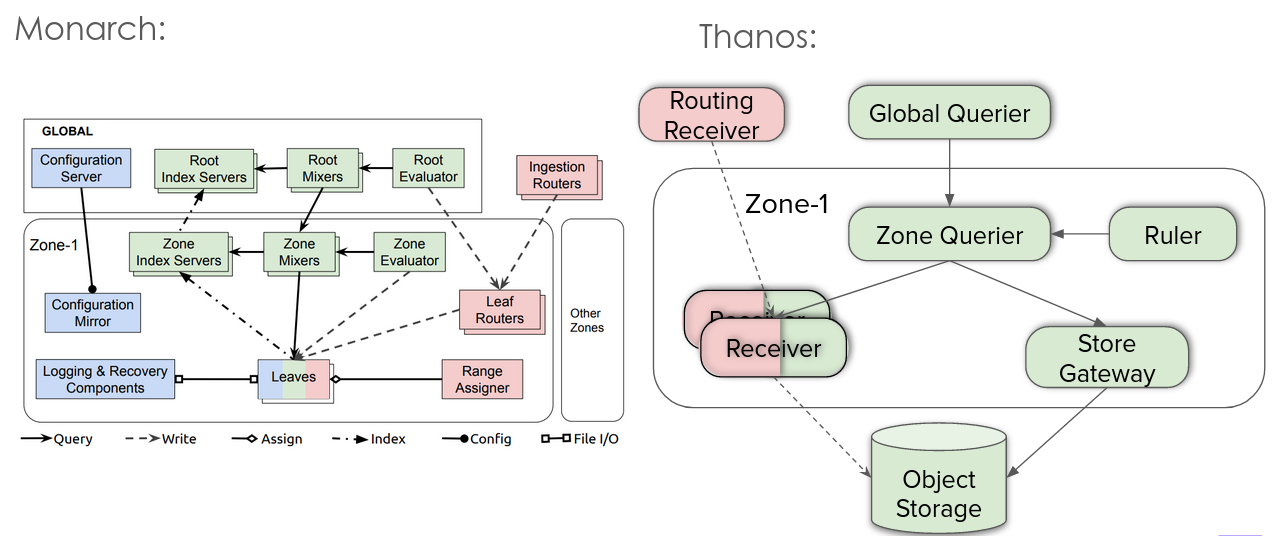
Přednáška Barteka Plotka a Bena Ye byla založena na srovnávání systému Monarch, globálního monitorování používaného Googlem, a projektu Thanos, což je CNCF incubating project. Srovnání proto, že Monarch je proprietární a Thanos je open source. Čili jestli má open source odpověď na dané řešení.
Chlapci postupně procházeli klíčové pasáže z Monarch white paperu a srovnávali je s architekturou Thanosu. Někde to chtělo trochu představivosti, ale většinou srovnávání fungovalo. Samozřejmě, je potřeba mít na zřeteli, že Monarch je battle-proved řešení, kdežto Thanos je rozvíjející se projekt. Ale vypadá nadějně.
Getting Started with Grafana Tempo: High Volume Distributed Tracing Built on Top of Object Storage
Joe Elliott je zaměstnancem Grafana Labs a stvořitelem Grafana Tempo, což je high-scale distributed tracing system, využívající OpenTelemetry. Přednáška byla převážně live demo s ukazování spousty Grafana dashboardů a jelikož nejsou k dispozici slidy, tak si z ní nic napamatuji. Ale pěkné to bylo.
PostgreSQL Network Filter for EnvoyProxy
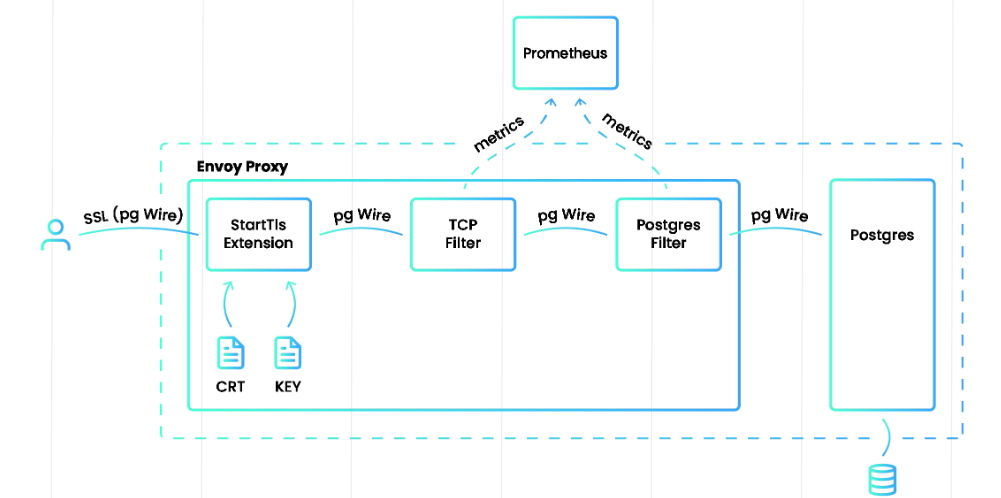
Fabrízio Mello a Alvaro Hernandez jsou z firmy, která nabízí support pro PostgreSQL a přišli se zajímavou myšlenkou — proč dělat klasický monitoring Postgresu se všemi agenty a restarty databází, když všechny potřebné informace jsou už obsaženy ve Frontend/Backend Protocolu, kterým komunikuje klient s databází?
Fígl je v tom, dekódovat zmíněnou komunikaci a metriky z ní vytáhnout. Takže dopsali do Envoy Proxy network filter, který právě takové dekódování a sbírání metrik dělá. Elegantní řešení!
Proper Monitoring: Applying development practices to monitoring
Jason Yee měl lightning talk ve formě vlogu. Bylo to sice osvěžující a zábavné, ale taky si z toho po pár dnech už nic napamatuju. Nicméně myšlenka byla trochu podobná tomu, co řeší Infrastructure as Code — převzít vývojářské techniky a best practices a aplikovat je v nové oblasti, v tomto případě monitoringu. Například mít Grafana dashboardy v Gitu, dělat testování dashborardů (že reagují podle očekávání) apod.
Monitoring MariaDB Server with bpftrace on Linux: Problems and Solutions
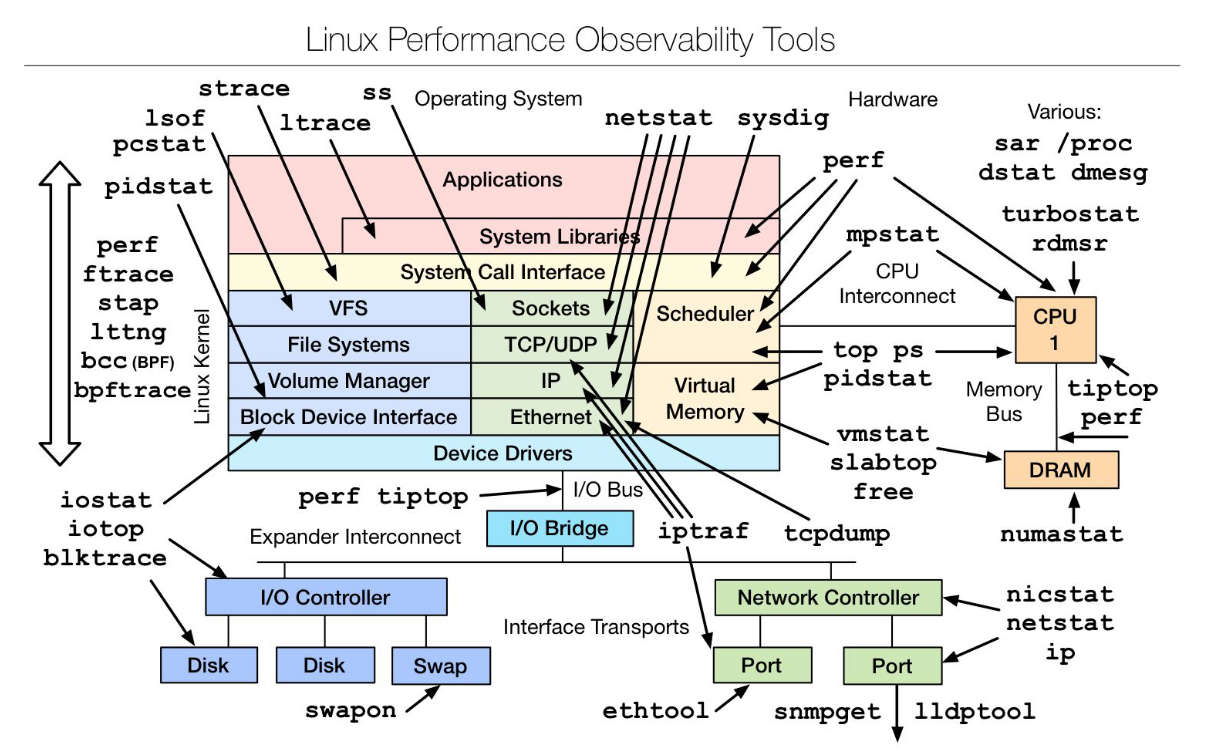
Valerii Kravchuk měl hodně low-level přednášku jak na Linuxu monitorovat MariaDB. Jakmile začal Valerij mluvit o linux kernelu, tak mě ztratil. 🤷♂️ Takže myšlenku přednášky bych shrnul jako:
Use modern Linux tracing tools while troubleshooting MariaDB server!
Performance Analysis and Troubleshooting Methodologies for Databases
Peter Zaitsev měl obecný přehled tří hlavních performance metodologií, které se využívají v distribuovaných řešeních:
A ačkoliv to mělo v názvu pro databáze, tak to bylo hodně obecný a o databázích to moc nebylo. Což vůbec nevadilo — jako přehled (pro začátečníky) to byl fajn.
Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
Poslední přednášku měl Alejandro Saucedo a moc k ní nemám co napsat (opět chybí jak slidy, tak video), jen že byla pěkná a zajímavá — jak monitorovat machine-learning rešení a to jak při trénování modelů, tak při produkčním využití.
Suma sumárum
Musím říct, že z roomu Monitoring and Observability jsem měl stejně příjemný pocit jako ze včerejšího Golangového. V případě monitoringu se hodně přednášek točilo v ekosystému Promethea a Grafany (a vlastně znova i toho Golangu) a z nich vycházejících řešení. Budu se muset na tuhle oblast trochu zaměřit, protože mi tady pořád zbývá pár studijních restů.